What is Dynamic Parallelism?
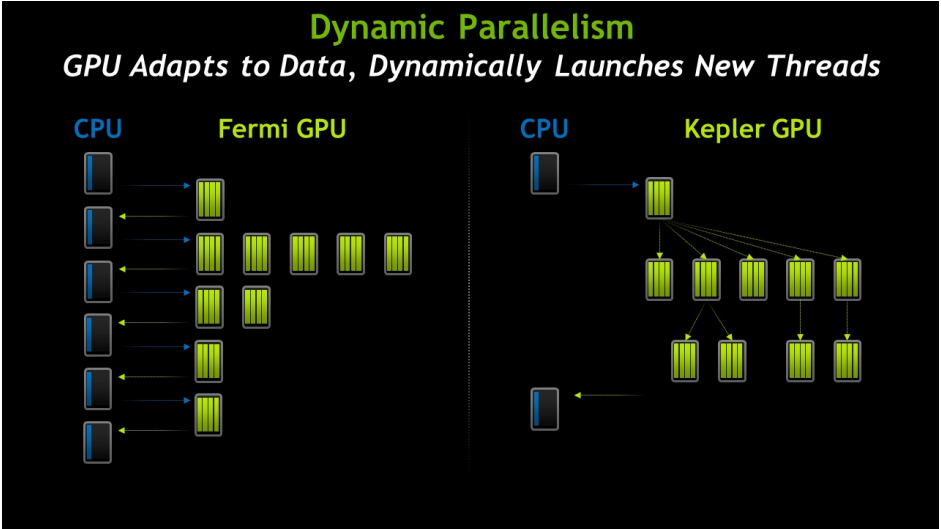 |
| Nvidia 2013 |
In order to make use of dynamic parallelism you must have an Nvidia GPU with compute capability 3.5
Dynamic Parallelism Example
As with every first code example we will look at a simple 'hello world' program which uses dynamic parallelism.

Here we have two kernels, the parent kernel and the child kernel. Out parent kernel calls the child, waits for it to complete its work and then carries out some work of its own.
When we initially try and build this code using visual studio we will get the following error.
Visual studio is complaining that we can only call kernels within kernels if we have a card of compute 3.5 or higher. To let visual studio know that we do infact have a suitable card we need to change a few properties.
To do this we open up the project properties by right clicking on the project.


The first setting we need to change is to tell CUDA to generate relocatable device code by selecting 'Yes (-rdc=true)'

Next we have to tell CUDA to use compute 3.5 by changing the code generation to 'compute_35,sm_35'

We then need to tell the runtime library to use the multi threaded library. If we are in debug mode we select 'Multi-Threaded Debug (/MTd)' or if we are in release mode 'Multi-Threaded (/MT)'

Finally inside the linker properties we add an additional dependency to 'cudadevrt.lib'
After following these steps our project will now build successfully and we should get the following output.

This has been to mostly help remind myself how to set up visual studio in the future if i forget but hopefully it can help out a few other people as well.
Any questions or if you are struggling with anything feel free to send me an email at craigmcmillan01@outlook.com with blog in the subject and i will be happy to help.
hola, no se encuentran los pdb ni las dll, como las agrego? gracias
ReplyDeleteHi, nice tutorial :) do you know how to set the properties for dynamic parallelism with CMake?
ReplyDeleteHi, I started to learn dynamic parallelism using the simple "Hello Wrold" example, which is mentioned in this post. I made changes in all the settings that are mentioned. But, still I am getting the same error, like, Error calling a __global__ function("childKernel") from a __global__ function("parentKernel") is only allowed on the compute_35 architecture or above.
ReplyDeleteSystem details along with software versions used:
NVIDIA GeForce GTX 1050
Windows 7 (64 bit)
Microsoft Visual studio 2015
CUDA 9.1 version